
redis用sds(Simple Dynamic Strings)表示字符串

-
带长度:二进制安全,即不像C语言字符串依赖\0字符标识结尾,可以存储包含\0字符的字符串,实际上可以储存任意二进制数据
-
兼容C语言字符串,即以\0字符结尾并直接指向字符串内容,这样可以像C语言字符串一样使用
-
缓存友好,因为整个sds就在一块内存
// 使用示例
sds mystring = sdsnew("Hello World!");
printf("%s\n", mystring);
printf("%c %c\n", mystring[0], mystring[1]);
sdsfree(mystring);
图示中的Header记录了字符串长度,定义以下结构体
struct Sds {
int len;
char* data;
}
len记录字符串长度(不包括data结尾的\0字符),data指向字符串数据,创建字符串时返回什么呢?以读取字符串第一个字符作为使用示例:
-
返回*Sds => sds.data[0],使用起来不是很方便,当然rust支持运算符重载这个不是问题,但C语言不支持运算符重载,那redis是怎么做到的呢?
-
返回 data => sds[0],使用很方便,也直观,和redis的使用示例一致,但这样无法释放Sds结构体本身的内存,因为无法通过data找到Sds的起始位置。
-
返回 &(sds.data) => (*sds)[0],比1还麻烦,虽然可以通过向后偏移usize类型大小字节数找到Sds结构体(sds-sizeof(int))。
注意,2和3是不同的,2是返回data字段存放的内存地址(指向字符串内容),而3是返回data字段本身的内存地址。图示是返回指向字符串内容的指针,2也一样,那redis是怎么做到通过字符串内容指针来释放Sds的内存的呢?细心点会发现Header和字符串内容是挨着的,之间没有间隙,只要知道Header占用内存大小就可以通过字符串内容指针向后偏移找到整块内存的起始位置。这就好办了:
Sds* mystring = malloc(sizeof(Sds) + len);
mystring->data = (char*)mystring + sizeof(Sds);
即Sds结构体和字符串占用内存一次性申请,结构体后面的内存用来存放字符串,这样可以修复2无法通过data找到Sds的起始位置这个问题(data-sizeof(Sds)就是了),只不过这样data字段就显得多余了,因为 (char*)mystring + sizeof(Sds) 这样就能找到字符串内容了,可以把data这个字段去掉,不过这样语义更加清晰:
struct Sds {
int len;
char data[];
}
data[]为柔性数组,语义为大小待定(实质内存大小占用为0)。原理理解得差不多就开始抄代码了:
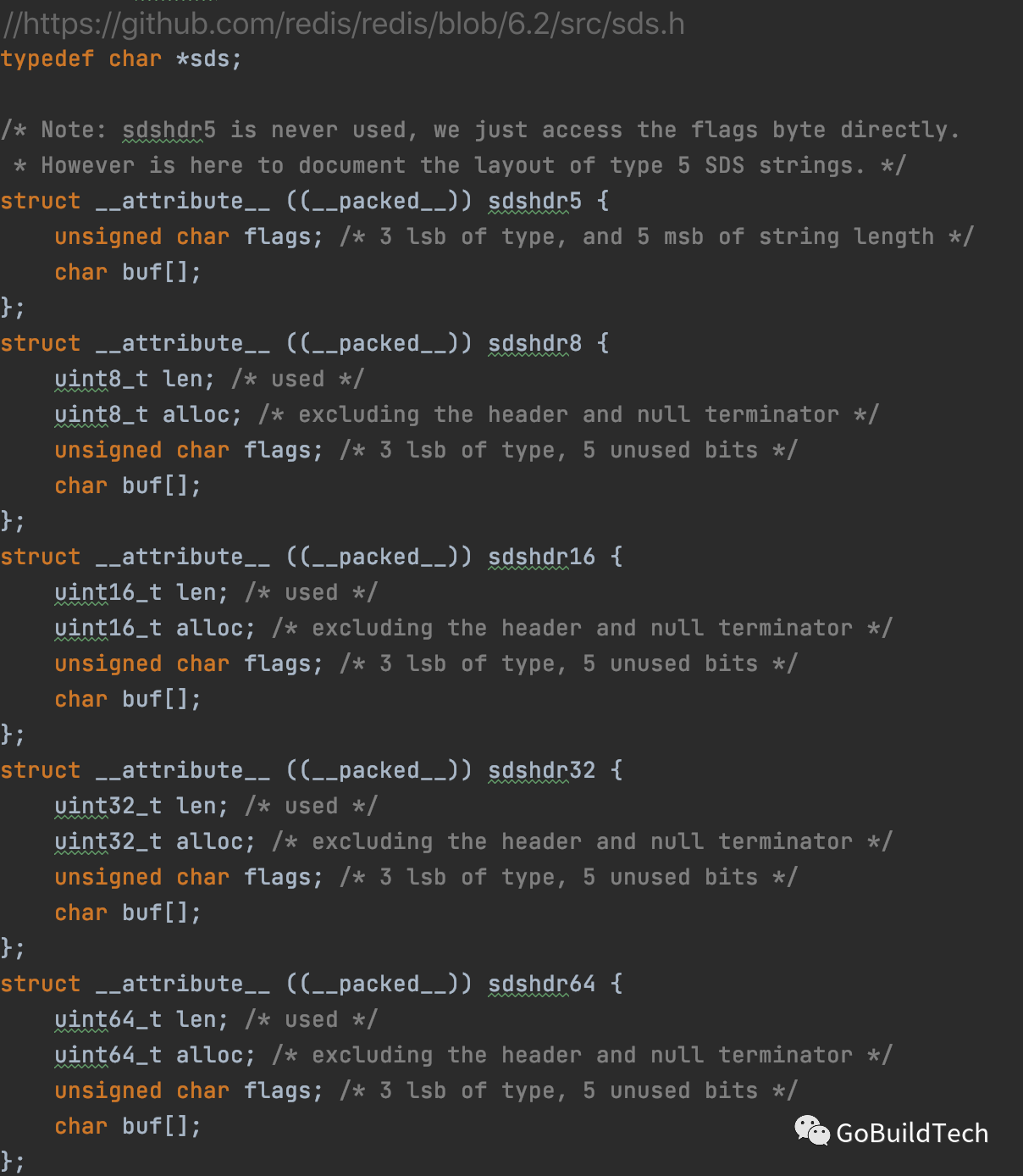
typedef char *sds:类型sds实质是char指针,
sdshdr5/8/16/32/64是Header,每种Header大小不一样,数字代表用于记录长度的位数(len字段);
alloc用来记录“buf”最大可用大小,注释说得很清楚,其不包含结构体本身大小和结尾的\0字符,alloc这个字段的意义在于sds长度发生变化时可避免重新分配内存,申请内存时多申请些并用alloc记下可用大小,字符串长度发生变化只要不超出alloc都可以只修改len而不用释放或重新申请内存,应该有种策略来根据len计算“最适宜分配”的内存大小;
flags用来记录当前的Header是这5种的哪一种,只用了低3位,flags字段一定要放在buf前面,这样位置才能“固定”;sdshdr5比较特殊,它用flags没有用的高5位来记录长度,没有单独的len和alloc字段,故只要字符串变长了都要重新申请内存,对redis这种频繁修改数据的应用来说并无优势,而且解释这种Header也比较费劲,redis实际上并没用这种Header(注释说的;确实也没找到创建sdshdr5的代码);
buf字段是柔性数组,字段本身大小为0,即不占用Header位置,数据内容从buf位置起始,sds指向这里;计算Header起始位置时,通过flags得知Header类型(指针向后滑1字节就是flags),然后往后滑该类型Header字节大小就是Header起始位置了。
attribute ((packed)) 编译属性用来告诉编译器不要将结构体中的字段进行内存对齐,这是必须的,因为flags字段只有1字节,编译器极有可能在flags后面填充字节来进行内存对齐,一旦填充了字节,将无法简单的通过buf的指针位置向后滑1字节来定位flags字段;rust可以用 #[repr(packed)] 来做:
#[repr(packed)]
struct SdsHdr16 {
// 2字节
len: u16,
// 2字节
alloc: u16,
// 1字节,会填充1字节进行对齐
flags: u8,
// 0字节
buf: [i8; 0],
}
struct SdsHdr16NoPacked {
// 2字节
len: u16,
// 2字节
alloc: u16,
// 1字节,会填充1字节进行对齐
flags: u8,
// 0字节
buf: [i8; 0],
}
#[test]
fn test_packed_attr() {
// SdsHdr16 size: 5
println!("SdsHdr16 size: {}", std::mem::size_of::<SdsHdr16>());
assert_eq!(std::mem::size_of::<SdsHdr16>(), 5);
// SdsHdr16NoPacked size: 6
println!("SdsHdr16NoPacked size: {}", std::mem::size_of::<SdsHdr16NoPacked>());
assert_eq!(std::mem::size_of::<SdsHdr16NoPacked>(), 6);
}
sdshdr8/16/32/64字段一样的,只是字段数据类型不一样,非常适合rust用泛型模板来实现,而sdshdr5既然没用的就不抄了;sds类型在rust中尽管也可以直接用裸指针,但把裸指针包裹在结构体内中可以对其实现方法,这样使用起来更加友好,而且结构体可以用上rust的所有权规则来管理内存:
#[repr(packed)]
struct SdsHdr<T> {
len: T,
alloc: T,
flags: u8,
buf: [i8;0],
}
type SdsHdr8 = SdsHdr<u8>;
type SdsHdr16 = SdsHdr<u16>;
type SdsHdr32 = SdsHdr<u32>;
type SdsHdr64 = SdsHdr<u64>;
struct Sds(*const i8);
这样比C语言版本简洁些;rust无柔性数组用0长度的数组代替,尽管语义模糊,但效果一样的。
有无必要将字符串分成4种?毕竟SdsHdr64可以保存另外3种字符串。看看各个Header的大小:
#[test]
fn test_sdshdr_size() {
// SdsHdr8 size: 3
println!("SdsHdr8 size: {}", std::mem::size_of::<SdsHdr8>());
// SdsHdr16 size: 5
println!("SdsHdr16 size: {}", std::mem::size_of::<SdsHdr16>());
// SdsHdr32 size: 9
println!("SdsHdr32 size: {}", std::mem::size_of::<SdsHdr32>());
// SdsHdr64 size: 17
println!("SdsHdr64 size: {}", std::mem::size_of::<SdsHdr64>());
}
SdsHdr8 size: 3
SdsHdr16 size: 5
SdsHdr32 size: 9
SdsHdr64 size: 17
假设字符串长度不超过128,平均长度为10(很多应用只用redis来存放整数id的,10位整数已经很大了),计算下内存有效使用率:
#[test]
fn test_mem_usage_rate() {
fn the_rate(kind: &str, waste: usize, effect: usize) {
println!("{}: {:.2}%", kind, (effect as f32/(waste + effect) as f32) * 100.)
}
let effect = 10usize;
the_rate("SdsHdr8", std::mem::size_of::<SdsHdr8>(), effect);
the_rate("SdsHdr16", std::mem::size_of::<SdsHdr16>(), effect);
the_rate("SdsHdr32", std::mem::size_of::<SdsHdr32>(), effect);
the_rate("SdsHdr64", std::mem::size_of::<SdsHdr64>(), effect);
}
SdsHdr8: 76.92%
SdsHdr16: 66.67%
SdsHdr32: 52.63%
SdsHdr64: 37.04%
内存分配器往往多分配内存,实际可能更加低。这样看来还是有必要分成4种的,缺点是这样实现代码会复杂些,而且程序执行效率会低些,因为CPU访问机器字比非机器字快、类型判断(通过flags计算出属于哪种Header)也有开销。
完整代码 https://github.com/iiibui/redis-rust-copy/blob/main/src/sds.rs
https://mp.weixin.qq.com/s?__biz=MzIxNzE5NDUyNQ==&mid=2247483675&idx=1&sn=119d34dce9edd0c95d28542a1941da6a